AIOps: Boosting IT operations with machine learning
Marta Valkavičiene
November 27, 2024
Table of contents
The rise of artificial intelligence and big data has paved the way for a new approach to IT operations: AIOps (artificial intelligence in IT operations). By using machine learning, AIOps enables increased automation, deeper insights, and most importantly for NordVPN—less downtime.

What is AIOps?
The global scope of NordVPN generates an avalanche of variable data that affects our user experience. With such a huge volume, our data analytics team is always on the lookout for ways to automate incident response protocols. These protocols involve diagnosing issues, resolving them, and then performing root cause analysis to avoid them happening again.
An AIOps model processes data points from all kinds of systems and processes – syslog, SNMP, configuration changes – and looks for specific issues they’ve been trained on. It then automatically feeds back intelligence, diagnostics, and recommended actions to our IT team, enhancing accuracy and reliability in their operations.
Let’s look at the various approaches to incident response (IR) management.
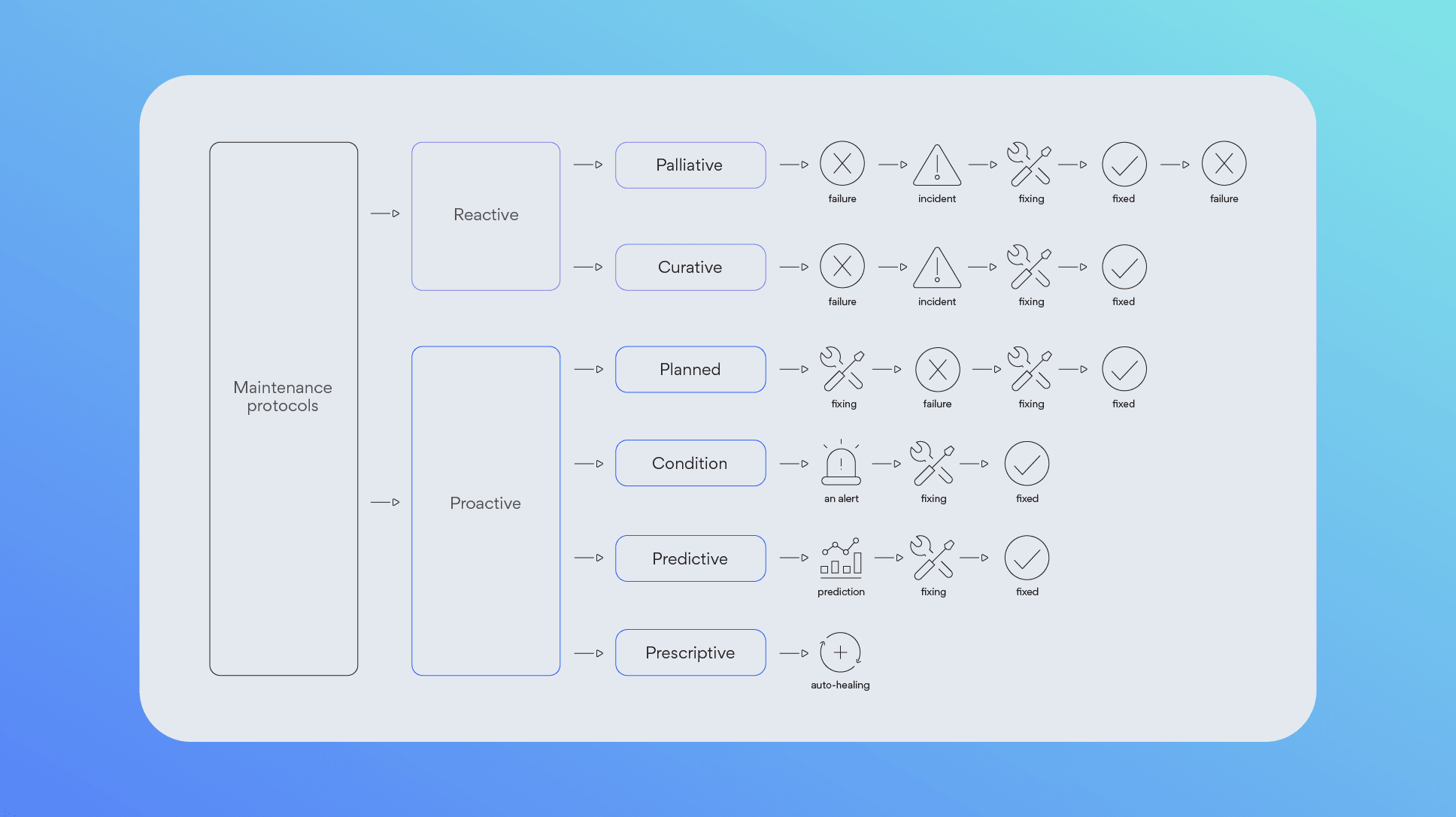
IR maintenance protocols overview
Most incident management steps are performed by system administrators, site reliability engineers, and similar personnel, depending on the issue. Alerting is usually based on simple rules (“if X increases, Y will decrease and we should alert Z”) when in reality the relationships between hundreds of parameters and dimensions in our system are anything but simple. We’re typically reacting to results rather than accurately predicting things because so many situations are not perceptibly related or logically connected.
IR maintenance protocols can be broadly divided into two main groups, reactive (reacting after an incident occurs) and proactive (acting before the incident occurs). To be precise, let’s drill down into these main groups' more specific subcategories.
Reactive
Palliative: Fix the issue and assume it won’t occur again. No further actions taken.
Curative: Fix the issue, assume it won’t occur again, but perform root cause analysis to be sure.
Proactive
Planned: Intentionally break our own systems to identify and fix potential issues.
Conditional: Select a threshold (usually on a parameter value) that might cause an issue. Once the threshold is reached, we send an alert and prevent the problem.
Predictive and prescriptive categories are the most efficient IR protocols, but this comes at a cost: they’re also the most difficult to implement. With AIOps, however, they become more viable.
Predictive: Utilize machine learning or big data analysis to predict and fix a potential issue before it occurs.
Prescriptive: The ‘holy grail’ of AIOps. The system does everything automatically.
Now that we have an overview of IR protocols, we can explore how AIOps can enhance each phase, from perception to action.
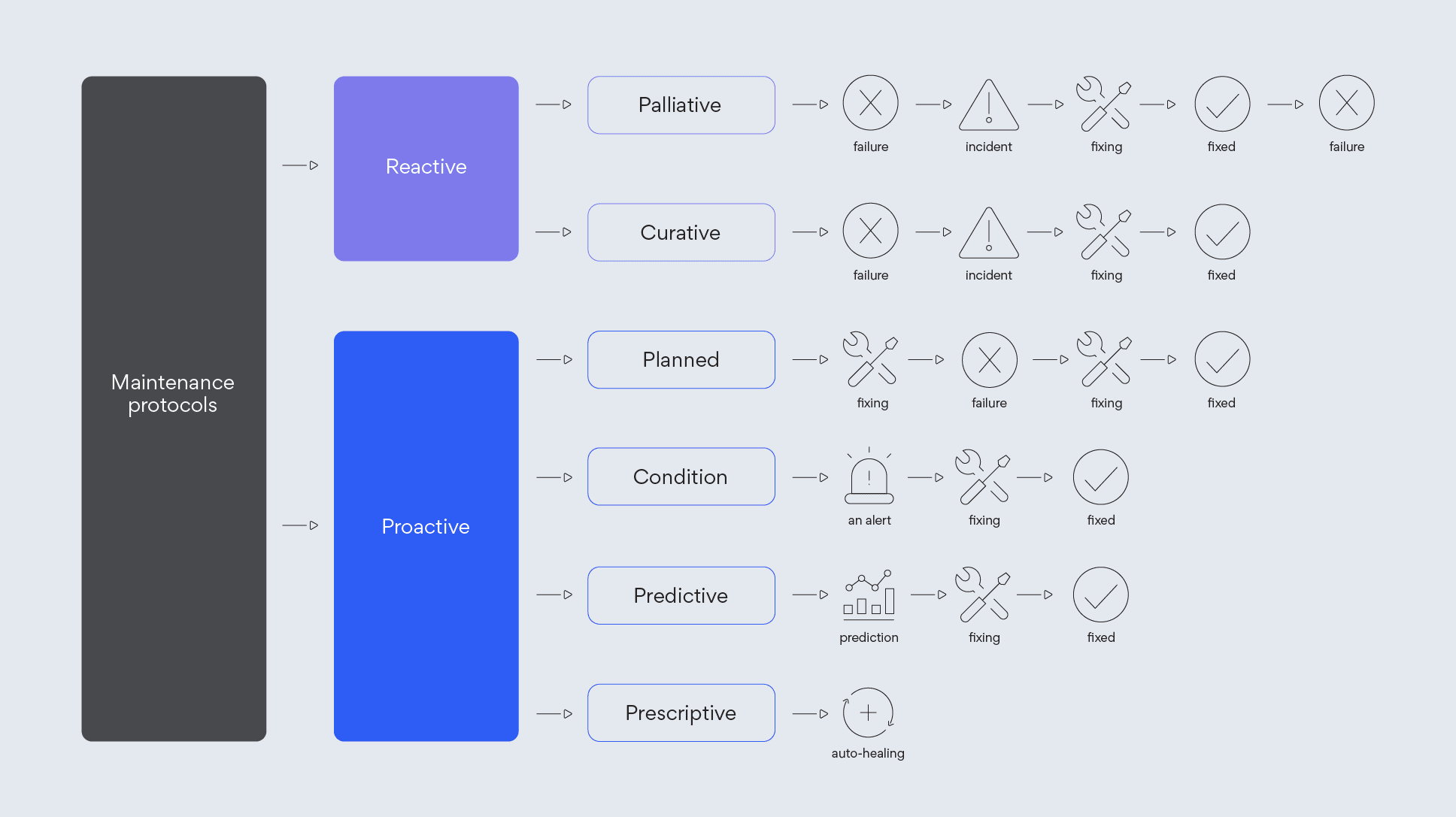
The spectrum from reactive to proactive maintenance protocols. AIOps is about being as proactive as possible.
How AIOps can improve our incident response
Perception: With AIOps, we’re not limited to one layer of data as with most standard IT maintenance protocols. Instead, all data layers and telemetry are simultaneously integrated – technical (servers, RAM), application (events), functional (network traffic, API endpoint results), and business (product metrics, KPIs). A comprehensive approach like this, which leverages real-time as well as historical data, is risky but offers significant upside potential.
Why the risk? With machine learning, it’s difficult to evaluate whether the model has properly calculated the relationships between data across layers. We can lose transparency during decision-making, and some decisions might seem illogical from a human perspective. This is important to keep in mind when using AIOps.Prevention: The ideal AIOps stack spots vulnerabilities and potential failures before they occur. For example, if a server is reaching a critical CPU limit, the platform automatically directs the API to stop recommending that server to newly joining users. New users are spared a sluggish connection while those already connected don’t experience any downtime. While load balancing is a common strategy, AIOps can elevate the process and adapt to long-term trends like seasonal fluctuations, dynamically adjusting server limits to ensure a smooth user experience.
Detection: AIOps models excel at spotting anomalies in established trends and patterns. Anomalies can pop up from anywhere and are often caused by external factors or faulty monitoring, which can be detected by an AIOps system hooked up to outside data feeds and APIs. Automatically detecting system slowdowns, errors, and security vulnerabilities enables us to avoid downtime and ensure a stable service for our customers.
Location: In-depth analysis of the root cause and location of the issue. AIOps will point out a specific set of components and variables that might have triggered an incident. Again, this will not be limited to internal factors only, but also consider external factors (e.g. network conditions, number of users and their behavior, and similar).
Interaction: Prioritizes and triages incidents, suggests corrective actions, and flags issues that require human input. Our team prioritizes issues based on the number of users that would be affected or at risk if a certain fault is not prevented. Additionally, AIOps can utilize prepared responses to specific situations based on historical data and incident resolution patterns.
Okay, this all sounds great! So why haven’t we done this yet?
AIOps implementation checklist
Need: First off, evaluate whether you actually need to leverage AIOps. If your operations team is typically facing more incidents than they can comfortably handle, it might be time to change. In our case at NordVPN, with an ever-expanding customer base, server requirements, area coverage, and platform offering, AIOps was a necessary optimization.
Team: An effective AIOps team requires a diverse set of roles, including data engineers and scientists to build and refine the AI models, and data analysts to extract useful insights. Engineering across DevOps, site reliability, and full stack ensures seamless integration, process automation, and system performance/scaling. Security specialists and project managers oversee the security and overall workflow of the project.
Hardware: Appropriate processing power, a decent amount of storage, and high-speed networking capability.
Software: Big data platforms (detailed below), ETL tooling, selected ML and AI tools, CI/CD tools, containerization platforms (Docker/Kubernetes), and monitoring tools.
Data: The data management platform generally has to be built from the ground up and include all relevant ingest data, such as event logs, traces, incident reports, etc.
Building a platform for that kind of scale is a huge job. There are third-party AIOps platforms out there, but they still require a major effort to align with your specific needs and often necessitate a data lake to centralize your data. You’ll also need the appropriate APIs.
Trust: It takes a mindset shift in your team or company to trust models over humans to diagnose incidents correctly. Don’t pass over this one—it’s key to successfully adopting new IT approaches like AIOps. You could start by gradually incorporating models in low-risk scenarios or incident patterns. Your team can experience the advantages of AIOps firsthand, which will build confidence and trust in this new approach.
To wrap up, we’ve found that a well-implemented AIOps system is an efficient way of bringing excellent service to customers. Equipped with deeper insights and increased automation, our IT team was able to shift focus to priority incidents and innovation with AIOps.