RabbitMQ: best practices and advanced use-cases
Dmitrijus Glezeris
May 5, 2021
Table of contents
The web may be a modern miracle, but it’s also unreliable, glitchy and brittle. RabbitMQ will help you resolve issues when it comes to real-world applications. It can give your users a better experience and make your life much easier.


What is RabbitMQ?
RabbitMQ is a popular open-source message broker. Message brokers enable applications to exchange information. They translate the messages from one protocol to another and enable services and apps to talk to each other even if they are written for different languages and platforms.
In this post, we'll give you some tips and tricks to help you write a resilient code, which should help you out if and when things go wrong with your applications.
Why use queues?
Take, for example, the simple and straightforward task of sending a welcome email to a user:


1$emailSender->send($email);
Simple, right?
But when looking at this process, a million little “what ifs” instantly appear in my head and create doubts:
What if the email server is busy?
What if the network is down?
What if we make a mistake in the email-sending code and all the messages are lost?
As developers, we should always be aware of these risks and tackle them head on. One extremely effective way to approach the volatility of the internet is to use queues.
There’s one rule of thumb that helps a lot of developers sleep at night: always offload as much work as possible to the queue. And we at NordVPN are no exception.
With queues, we can safely add an email to the queue only to process it later:


1// publish to queue when the user registers2$emailPublisher->publish($email);3// consume from the queue in an another process and send an email4$emailSender->send($email);
You might think that the job is done, but that couldn’t be further from the truth. Even with the best technology, it’s natural to encounter various pitfalls and unexpectedly sharp edges.
Over the years we have accumulated certain AMQP practices, and you can use them to succeed in a glitchy real-world environment. Later in this post we’ll explain a few of them, so you can make your life easier when using queues.
Using retry queues
Here is our previous example:
1// publish to queue when the user registers2$emailPublisher->publish($email);3// consume from the queue in an another process and send an email4$emailSender->send($email);
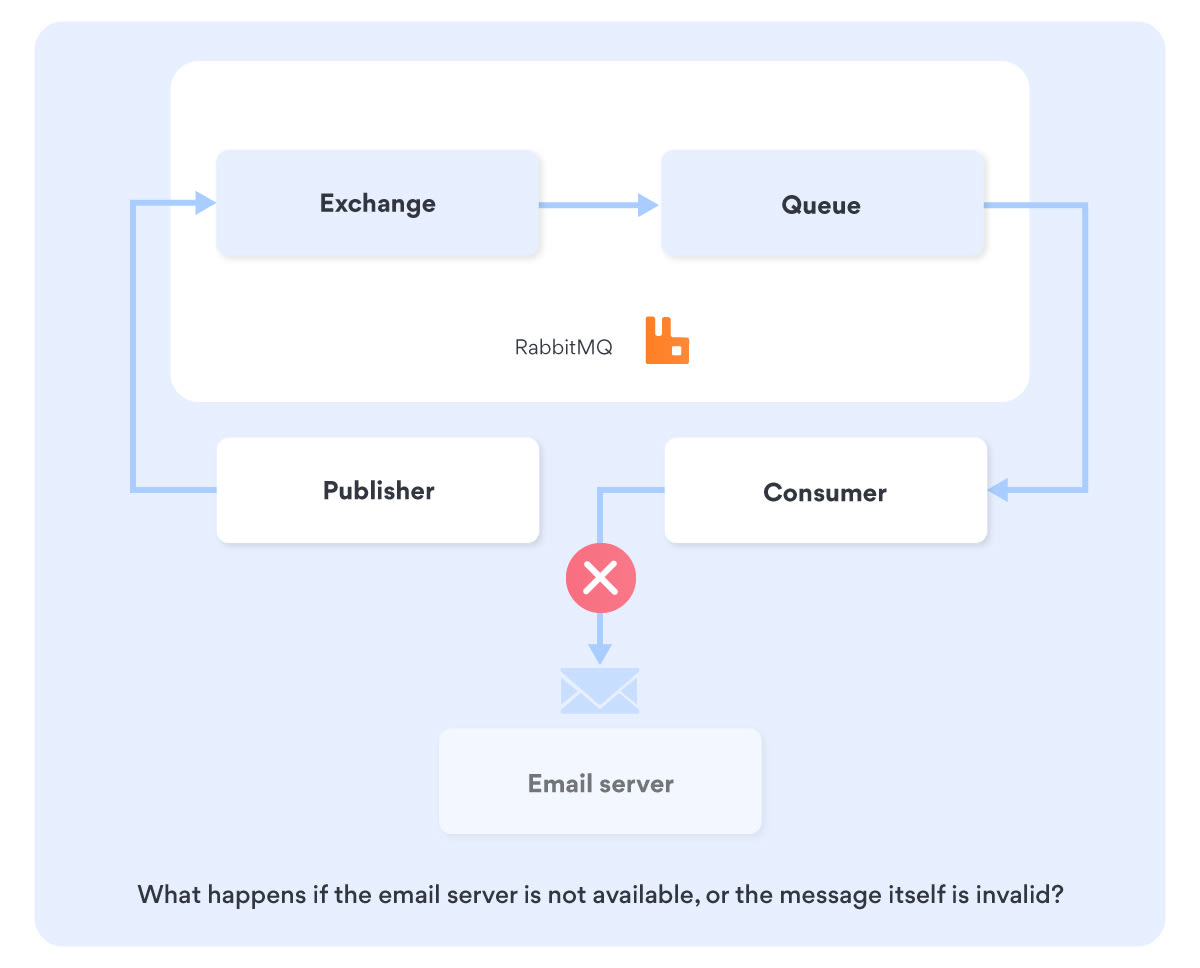
But what happens if the email server is not available, or the message itself is invalid?
Well, the common practice is to fail and requeue the message to the same queue. Then, the consumer will attempt to send the message next time it runs.
However, if we attempt to send the message over and over again, we risk performing a self-inflicted DoS attack. With a constant spam of requests, we are essentially kicking the email server when it’s down, just as it's trying to start up. Additionally, if the message itself is invalid we might block other valid messages that are in the back of the queue from being processed.
The solution is to declare additional retry queues where the message gets forwarded for not being processed in an expected way. Essentially, the message gets put into a “timeout” corner for behaving like a brat. Once the time is up, we forward the message to the main queue and attempt to consume it again:

1// declare a retry queue2$channel->queue_declare(3$retryQueueName,4false,5true,6false,7true,8false,9new AMQPTable([10'x-expires' => $queueExpirationInMilliseconds,11'x-dead-letter-exchange' => $mainExchangeName,12)]13);
Essentially, we declare a retry queue with the following properties:
Set x-dead-letter-exchange to the exchange that routes the message to the main queue after a message exceeds its expiration;
Optional: Set x-expires to a certain number of seconds since we want it to only exist when any problematic messages are present.
You can then publish to the retry exchange if any exception occurs:
1try {2$consumer->consume($message);3} catch (Exception $exception) {4$message->set('expiration', $nextRetryAttemptInMilliseconds);5$publisher->republishToRetryQueue($message);6}
We catch any unexpected exceptions and republish the message with an expiration property on the message. Once the expiration is up, the message will be moved to the original exchange for yet another attempt. In the meantime, while the failed message is in a “time-out corner”, the rest of the messages can be consumed.
$nextRetryAttemptInMilliseconds specifies how long the message needs to stay in the retry queue. We calculate $nextRetryAttemptInMilliseconds based on the x-death property:
The dead-lettering process adds an array to the header of each dead-lettered message named.
The more x-death attributes the message has, the more attempts were made to process it. This property allows us to increase the delay exponentially based on the number of times the message couldn’t be processed.
Keep in mind that the message gets redelivered to the exchange after a timeout. If multiple queues are bound to the same exchange, they will receive the message again and again as long as one of the consumers fails to consume the message and creates a retry queue.
One way to approach this would be to either use highly specific routing keys or use stateful consumers.
How to use stateful consumers
Imagine you get a phone call late in the evening from management with a terrible news: due to server issues some new users didn’t receive a welcome email, and we need to send it to them ASAP. What would you do?
Well, the solution seems simple – you just go through all users and publish an email job to the queue:
1foreach($users as $users) {2$email = $this->emailBuilder->build($user);3$emailPublisher->publish($email);4}
Then you deploy your code and run it in production only to receive an angry message from management telling you that some of the users already received an email beforehand. Now they received a second one because of your code. Yikes!
To prevent this you should always keep a record of all the processed messages on the consumer side of things with this code:


1$emailLog = $this2->emailMessageRepository3->findByUserAndTemplate($email->user_id, $email->template);4if ($emailLog !== null) {5return;6}7$emailLog = $this8->emailMessageManager9->createByUserId($email->user_id, $email->template);10$emailSender->send($email);
First, you search for an existing message log using certain criteria that lets you determine whether the record is unique to the user or not. If an existing email log exists, the message has already been processed, and we can just quit.
However, your troubles are not over yet. The management tells you that sometimes users still receive two emails. It seems you should use locking!
How to use locking
As I mentioned earlier, there is a problem with the previous logic. If you feed two consumers the same email at the same time, then the code…
1$emailLog = $this2->emailMessageRepository3->findByUserAndTemplate($email->user_id, $email->template);
…will return an empty emailLog for both of the consumers due to a race condition. At best, you might end up with a “Constraint violation” error if you have a unique index setup on the email log table. At worst, the user will receive a double email.
Due to the parallel nature of the consumers, race conditions are not uncommon. Therefore, if you plan to use any finite resource, make sure to use locking to limit access to it:


1$emailLog = $this2->emailMessageManager3->getOrCreateWithNewStatus($email->user_id, $email->template);4$this->lockingManager->lock($emailLog);5if ($emailLog->getStatus() !== EmailLogStatus::NEW) {6// someone else has processed our record, quit7return;8}9$emailLog = $this10->emailMessageManager11->createByUserId($email->user_id, $email->template);12$emailLog->setStatus(EmailLogStatus::DONE);13$this->emailMessageManager->save($emailLog);14$this->lockingManager->unlock($emailLog);
We first make sure that the database record exists. If not, the service will create a new record with an EmailLogStatus::NEW status. Then we immediately perform a pessimistic lock on the record to make sure no one else changes it.
Once the lock has been acquired, we check whether the record has already processed by some other consumer. If it hasn’t yet been processed, we process it and mark the record with a special EmailLogStatus::DONE status.
RabbitMQ: a powerful tool
As you can see, even when using RabbitMQ queues for straightforward tasks we encounter various challenges.
However, these are some of the most powerful tools at our disposal. Hopefully this blog post helps you to face these challenges yourself, and to enhance your users' experience.