Libdrop: File sharing through NordVPN
Lukas Pukenis
February 6, 2024
Table of contents
The Libdrop library allows NordVPN users to share files over Meshnet. In this article, we explain how we developed our file transfer system and the role Libdrop plays in it.


What is Libdrop?
Libdrop is a cross-platform library developed in the Rust programming language. It is compatible with Windows, MacOS, Linux, iOS, and Android. File sharing within the NordVPN environment is facilitated by the Libdrop library, which is available as an open-source resource on GitHub.
The goal of Libdrop implementation is to allow smooth and secure file sharing between users over Meshnet. The library should be easily integrated into the NordVPN application so API users can issue transfer requests, with the rest of the processes being carried out in the library.
Libdrop protocol
The Libdrop protocol enables peer-to-peer file sharing via both IPv4 and IPv6. In this process, the sender presents files to the receiver, who then selects specific files for download. Downloads are then initiated.
The transfer is live until one of the peers goes down or the transfer is explicitly canceled by either of the peers, after which the files are no longer available for download. This provides the user with a time window where they can decide which files they want to download now and in the future while the transfer is still up.
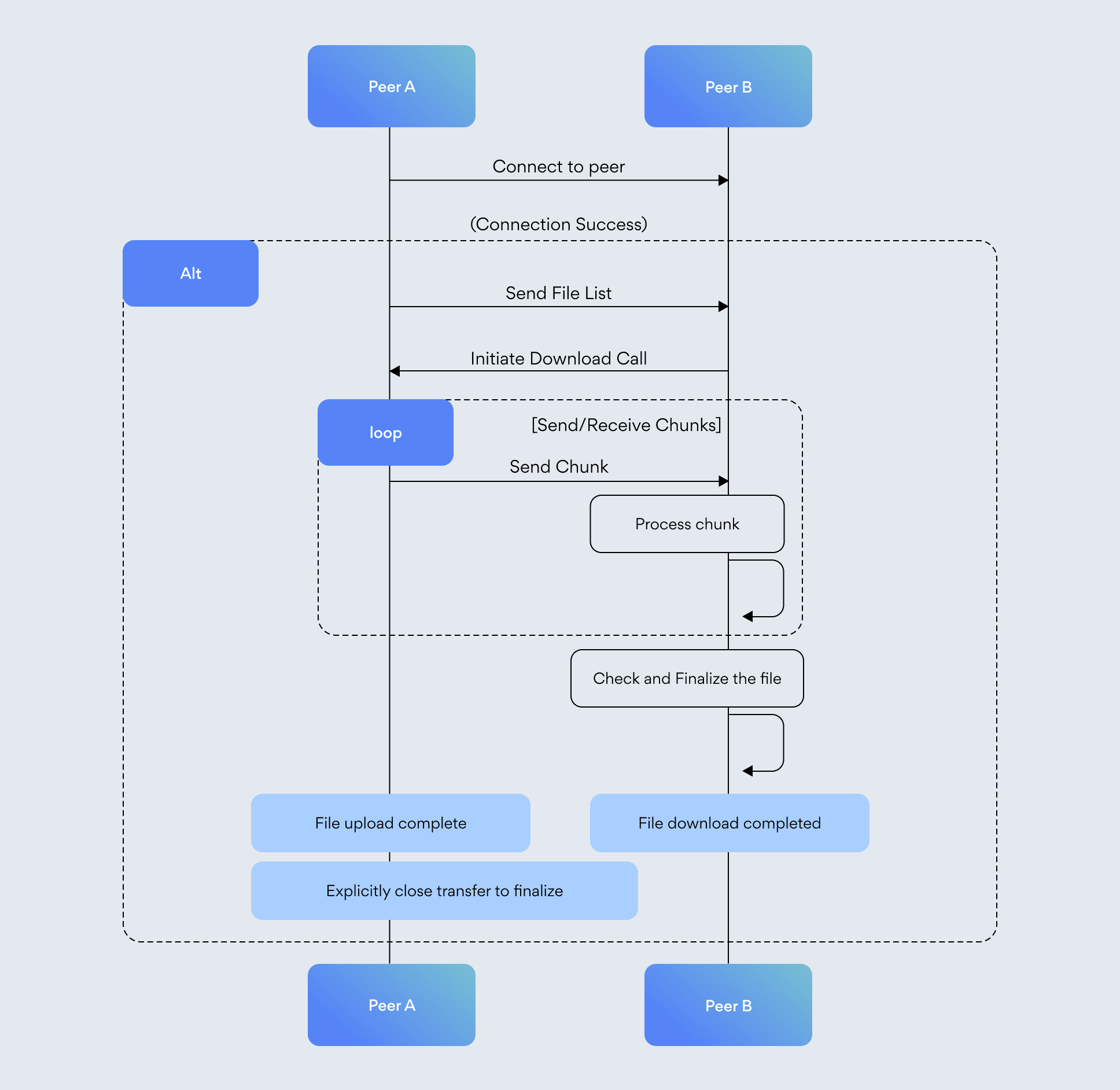
High-level overview of communication between two peers.
Communication and low-level details
Let’s take a closer look at the technical details of the communication process and how we developed our current setup.
gRPC
At first glance, it seemed evident that our easiest course of action would be to focus on the HTTP server and client because this is very easy to use and understand as well as being a time-proven technology. We could make a REST endpoint and just proceed with a regular HTTP download.
To enhance speed and control, we opted for gRPC. Because gRPC is a binary protocol, it has less overhead. It is also strongly typed, making errors harder to introduce. gRPC technology automatically generates the code needed for both the client and the server, making it an excellent fit. In fact, Libdrop was originally built on gRPC.
Initially, it was very convenient to use — both the client and the server code just worked. We could issue a certain call via the wire and expect the appropriate function to be called on the peer.
WebSockets
Unlike gRPC, WebSockets is not strongly typed, which offers a degree of flexibility. This flexibility comes at the cost of making it easier for bugs to appear. However, there's no automatic code generation, which is a plus.
The ability to easily introduce versioning was another advantage. We just need to have the URL in the form of "ws://{addr}/drop/{version}/query." It also helped that WebSockets is a fairly easy-to-understand technology that works in tandem with HTTP so the traffic can be inspected easily as well as debugged.
Choosing WebSockets turned out to be a wise decision. It led to a reduction in code complexity and greatly enhanced our understanding of the data flow. Plus, having written the code ourselves, we felt fully in control of the system.

Simplified representation of backward compatibility between Libdrop versions.
Rust and Tokio
Due to the nature of the Libdrop library’s heavy IO and event-driven architecture, the codebase contains a lot of asynchronous flows which could have been a tough problem. However, Rust’s great implementation of async alongside the Tokio library proved to be a great combination in dealing with this and avoiding potential crashes.
Rust shines because the borrow checker is really persistent about lifetimes and safety while developing because it prevents you from compiling incorrect code that breaks ownership rules.
We are also fairly safe from panics because we spend most of the time in Tokio tasks, and those are executed in catch_unwind. This means that if the Tokio task panics, it will simply yield an error instead of tearing the whole thread down.
Still, not every place in the codebase runs in a Tokio task, and so for those cases where a Tokio task is not involved, we tune Rust linter to detect unwrap() calls in the codebase that could potentially invoke a panic handler.
NordVPN uses Rust in numerous libraries, and panics are handled in custom panic handlers. These handlers wrap the error and emit it via callback so the API user receives it and can properly log it.
API and the dilemma: To block or not to block?
We’ll now explore the choices we made around our API.
SWIG and UniFFI
For the API we used SWIG, which was already battle-tested and proven by libraries such as Libtelio. SWIG automatically generates FFI binding code for all target platforms, but it’s not without limitations. While it’s very easy to pass primitives such as integers and strings, higher-order structures are not that comfortable. In a compromise, we accept certain parameters as JSON strings.
JSON strings, while slightly less optimal, are a great solution to the problem. All mainstream languages know how to parse it or have a popular library ready to do so. The downsides to JSON strings are less type safety and a need for greater control to avoid breaking the conformity.
To maintain conformity, we used JSON for emitting callback data towards the application, such as file or logging events. We needed to conform to a type and not change it because there’s no type safety involved. Therefore, any changes might break a JSON parser here or there. Even adding a new field might be a breaking change for some parsers, so major library version upgrade is required, which is annoying.
Due to concerns over SWIG, we opted out of migrating to UniFFI in the library teams. This allows us to write standard Rust code and define UDL, which is similar to SWIG. UniFFI replaces the need for client-side scaffolding, which was lacking in SWIG. Previously, we had to wrap C-style calls in Rust for each function, a cumbersome process especially for callbacks, and SWIG doesn't support features beyond what the C ABI allows. UniFFI enables the passing of Rust structures containing various supported POD types, simplifying the process.
Event-driven architecture and reporting
One question that arose around the API was whether or not we should block it. Based on the API users, we opted to not make the API block and communicate via events. This provides more complexity on the API design side, but it provides an event-driven API and means that API users don’t need to care about threads. App developers are usually experienced in working with callbacks, so this architecture suits them well.
Callbacks are used for event notification and reporting, so the API user can receive reports and log them where appropriate. Events are for reporting. Both events and reports are passed on as JSON-encoded strings.
Errors are reported when the parameters to the API are incorrect or when a runtime error is encountered.
Types of events
Events are emitted for various milestones:
A transfer was requested.
The transfer was successfully queued (the API returned no error) and contains all the paths collected.
A file upload/download was started, finished, or failed.
A file upload or download progressed.
We chose SQLite for its flexibility and cross-platform availability, and because it offers a strong query system that makes it user-friendly.
The widespread use of SQLite in various applications gave us added confidence in its reliability and performance, making it an easy choice over alternatives like JSON files or custom binary formats.
In cases where we fail to open or migrate the SQLite database successfully, we can remove it entirely and try again. If it fails again, we can then use an in-memory database that provides proper functionality while the app is alive.
High Availability
To send a file effectively, both peers need to be online simultaneously. This is a fundamental requirement, and the only alternative is to use third-party file hosting. To streamline the process, we introduced resumable transfers.
When a network error occurs, we consider the transfer as still valid and eligible for resuming, rather than declaring it a failure. While it might sound simple to disregard network errors, the real challenge arises when peers issue API calls when offline. Determining the accurate state of a transfer becomes complex. This led us to discover conflict-free replicated data types (CRDTs). Implementing CRDTs necessitated API changes. Previously, we permitted the redownloading of a canceled file, but now all files are in one of the following states:
Rejected
Failed
Completed
This approach has simplified the logic and understanding of LiDrop's workflow, which is beneficial, considering the extensive changes required to implement this functionality.
We of course then needed to introduce syncing of the states and ability for peers to check if the transfer is still alive on the other end — once it’s reachable. To ease the pain for app developers, everything initially was encapsulated entirely inside of LibDrop — it was invisible to the apps how it was working, however, not free of charge — LibDrop needed to continuously retry establish connections and do so with some delay to not saturate the network. This, however, proved to provide delays when peers were actually online, and we opted for a new API call — norddrop_network_refresh().
The new API call was deliberately chosen to be free of arguments, so it would be hard to call it incorrectly. This way the documentation is very simple. Once peer availability changes to online, issue the API call, and LibDrop will take care of the rest.
This proved to be a good choice because initially, if we would retry every 10 seconds, it might happen that the peer becomes available immediately after we tried and failed, meaning there will be an almost 10-second delay until next retry. With the new API call, it’s almost instantaneous.
File validation: Ensuring integrity from start to finish
As part of our commitment to ensuring a reliable file transfer process, we take several precautions. The moment a file is selected for upload, we immediately fetch its metadata, specifically capturing its size and checksum. This information is then shared with the receiver to ensure both parties have synchronized data right from the start.
During the actual upload, we keep a close eye on the data transfer. We compare the size of the transferred data with that of the received data, allowing us to detect any inconsistencies. If a discrepancy is found, the transfer is terminated, ensuring that only accurate and complete files proceed.
At the receiving end, a fresh checksum is calculated once the correct amount of data is received. If this calculated checksum doesn’t align with the initially shared checksum, the transfer is terminated. In such cases, the transfer is reported and stored as a failed transfer on both ends.
Threat Protection
In both Windows and MacOS, files often carry metadata indicating their origin. Without this information, antivirus software would need to scan each and every file for threats, which isn't efficient.
Applications regularly produce many files, the majority of which are legitimate and harmless so it’s common practice to embed specific markers within these files. This allows antivirus tools to identify and scan files faster.
On Windows and MacOS, we immediately attach these markers once files are downloaded. This ensures that the Threat Protection scanner can promptly identify and assess them, leaving no gap during which they might be accessed without a prior security check.
MacOS uses kMDItemWhereFroms while Windows uses Zone.Identifier.
Socket security
Finding the protocol and communication method used by Libdrop is straightforward. The port we use is 49111, and the address is in the format ws://{addr}/drop/ (this can all be seen in the source code provided on GitHub).
While it's true that you can bypass Libdrop by directly connecting to this URL with cURL or similar tools, this is a situation we'd like to avoid. Our aim is to maximize usability and minimize the risks for users.
Since we considered user experience, we also explored the idea of automatically accepting files from trusted peers. However, we recognized the potential risk of someone abusing this feature to spam others and so decided against it.
To enhance security, we implemented an authorization system based on Meshnet keys. These keys are retrievable via API after successful user authentication. Since NordVPN is consistently aware of peer public keys, we're able to use this information to validate connections at the Libdrop communication level. If a user fails the authorization process, the transfer is terminated — no questions asked from the receiver side.
To accomplish this, we employ HMAC with SHA-256 and generate a shared key using the Diffie-Hellman algorithm. When initiating a connection, the NordVPN app provides the public key of the peer. Combined with the private key we already possess from the time of initializing Libdrop, we're able to calculate this shared key. Both sides of the transaction do the same, and the process is only deemed successful if the keys match.
We're aware that this system isn't bulletproof. For instance, users might find a way to exploit a Linux CLI app. However, we believe these improvements represent a significant step towards creating a safer and more reliable experience for our users.
Permissions and user access
Integrated into the NordVPN application, Libdrop operates under the constraints of user permissions as enforced by the operating system. This ensures that users can only share files to which they have ownership rights. To initiate a file transfer, a connection between peers must first be established. Enabling file sharing for a specific Meshnet peer allows one to start receiving files from that device. Enabling file sharing for a specific Meshnet peer allows a user to start receiving files from that device. Disabling file-sharing permissions for a Meshnet peer will halt incoming transfers from that particular device. You can read more about file-sharing permissions here.
On the Linux platform, we faced an additional challenge because the app needed to run as root due to Libtelio’s requirements. Running Libdrop as root was out of the question because it would have unrestricted access to the entire file system. To navigate this issue, we set Libdrop up to run as a user process that communicates with the NordVPN daemon.
Fortunately, mobile devices didn't present the same issue, thanks to their robust sandboxing. Likewise, applications on Windows and MacOS operate with user permissions, so there were no concerns on those platforms either.
It’s worth noting that Libdrop isn’t designed for multi-user scenarios, because it uses a hardcoded port number, 49111. However, it can technically bind to different network interfaces without any problems.
File aggregation
To simplify the user experience and streamline integration, we designed Libdrop to automatically enumerate files in the paths provided. These paths can point to either individual files or directories, allowing for greater flexibility. This setup posed several challenges, however:
How can we recreate the directory hierarchy?
What do we do when we encounter a symlink?
What happens if there are too many files?
What are the issues with Android permissions?
Let’s take a closer look at how we overcame these challenges.
Recreating the directory hierarchy
For hierarchies, we used the same rename logic as we did with the files, but only for the root level directory. We only communicate the path with the peer starting at the root level of the provided path, meaning that if there’s a directory structure of C:\Files\Photos\Cats\Cute and the user adds C:\File\Photos, then we only send Photos\*. The receiver is unaware of the C:\Files portion. This was important because if the receiver was aware of that portion, personal details could be leaked.
Interestingly, directory separators are not cross-platform. Windows supports both \ and /, while Unix-based OSs (Android, iOS, MacOS, Linux) support only /. Initially, we just communicated with the path as-is, which then produced some fun results. Sending the path “Photos\Cats\1.jpg” from Windows to a Linux machine would produce a file with that name instead of two directories and one file when transferring a directory.
As an easy solution, we chose the following approach: when the user sends a directory and we aggregate a path, we split it with the native path separator and then glue it back together using the universal one — /. We can then use that path going forward.
Dealing with symlinks
We decided that when a symlink is encountered, we would return an error. This reduces the chances of possible security issues arising around certain files.
Symlinks reduce the visibility of operations, creating situations in which a user might think they are sending one set of files while in reality a different group of files is picked up.
What happens if there are too many files?
In Libdrop, we allow for certain configuration values when initializing the library, ensuring that it can be flexible across multiple platforms. To help with interoperability, we decided to add two values: file limit and file depth limit.
Including these two values means that deep directories result in an error. An error is also generated when the file limit is reached. We think it’s better to be explicit than implicit, and so we’d rather generate an error than send an incomplete file transfer.
Android permission issue
Using the transfer system on Android presented us with some challenges. In order to use the POSIX file system, the API needs appropriate permissions in the application manifest. Direct file system access requires that the application is placed within a single specific category, but this was a problem because NordVPN is not just a file or backup manager.
A solution was found when we did an experiment and found that upon selecting the file in Android, it was possible to detach the file descriptor. This enabled us to use POSIX with the provided descriptor:
Testing and dogfooding
We used Python and Docker to load the compiled library and imitate conversation between two peers. This allowed us to reproduce the bugs by writing test cases, easing our concerns about bigger changes in the codebase.
The testing framework allowed us to generate scenarios quickly using a Python API where we can imitate all the actions a user might take alongside the events we would expect as a result.
Tests can’t perfectly replicate what happens in real life, so we still constantly seek QA feedback alongside the relevant aggregated logs. Still, having an easy-to-use test framework proved to be very beneficial and boosted our confidence during development.
Meshnet protocol and wire safety
NordVPN's file-sharing feature is built on Meshnet, a peer-to-peer protocol. This design allows for the shortest possible data path between computers, eliminating the need for third-party cloud storage or service providers.
One caveat is that both Meshnet nodes must be online simultaneously for the transfer to take place. All traffic between Meshnet nodes, including file sharing, is authenticated and encrypted via WireGuard’s cryptography, ensuring that even Nord Security cannot access the contents of the files or the traffic being transmitted. You can read more about the Wireguard protocol here.
Thanks to Libtelio and Meshnet, Libdrop doesn’t need to use any encryption of its own, because double-encryption would be unnecessary. If you’re considering implementing Libdrop into your own product, you should integrate transport layer security (TLS), which should be fairly trivial to implement.
In summary, NordVPN’s File Sharing feature offers a secure, efficient, user- and API-user-friendly method for peer-to-peer file transfers through the Meshnet.